Power Automate Cloud – Sesión 07 – Resumen
Automatización de extracción de datos con AI Builder (Document Processing)
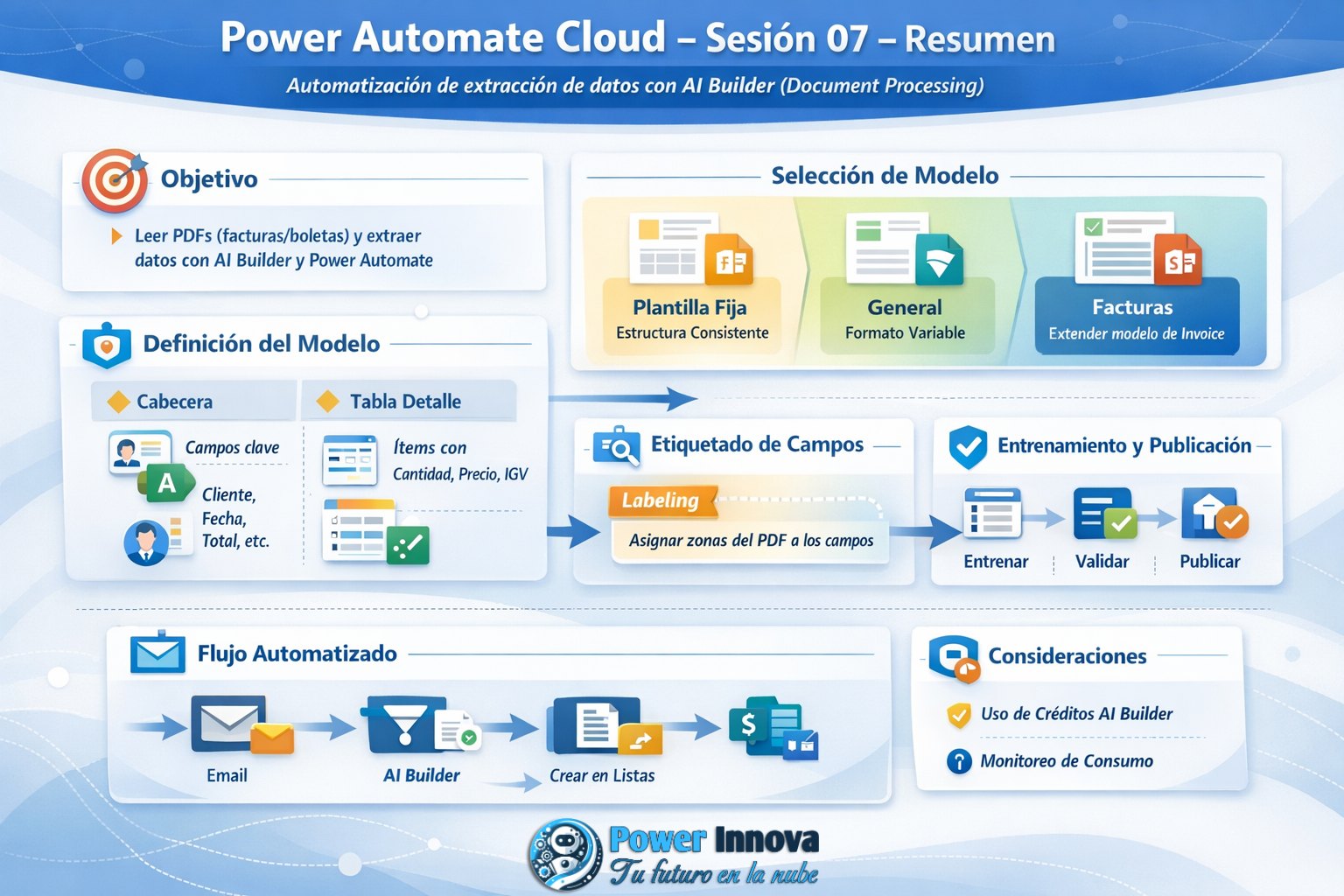
🎯 Objetivo de la sesión
Implementar una automatización completa para leer documentos PDF (facturas/boletas), extraer campos de cabecera y detalle mediante AI Builder (modelo personalizado), y registrar los datos en listas usando un flujo automatizado en Power Automate.
🧩 Temas tratados (vista general)
- AI Builder y modelos personalizados para extracción de información desde PDFs. [learn.microsoft.com]
- Elección del tipo de documento: Fixed template / General / Invoices y cuándo usar cada uno. [learn.microsoft.com]
- Diseño de campos (cabecera) y tabla de detalle (líneas de ítems). [learn.microsoft.com]
- Etiquetado (labeling): “match” entre campos creados y zonas del documento. [learn.microsoft.com]
- Entrenamiento, validación y publicación del modelo para poder usarlo en flujos. [learn.microsoft.com], [learn.microsoft.com]
- Construcción del flujo: correo (Outlook 365) → adjuntos → Process documents (AI Builder) → Create item en listas. [learn.microsoft.com], [learn.microsoft.com]
- Consideraciones de créditos/capacidad de AI Builder y monitoreo de consumo. [learn.microsoft.com]
🔑 Conceptos clave
- Power Automate Cloud: plataforma para crear flujos automatizados con conectores (Outlook, SharePoint, AI Builder). [learn.microsoft.com]
- AI Builder (Document processing): permite entrenar un modelo para extraer campos y tablas de documentos (PDF, imágenes). [learn.microsoft.com], [learn.microsoft.com]
- Etiquetado (labeling): proceso de indicar al modelo “de qué zona” del documento sale cada campo (y cada columna/filas del detalle). [learn.microsoft.com]
- Salida del modelo: para usar datos en el flujo se recomienda seleccionar “{campo} value” (y opcionalmente revisar confidence score). [learn.microsoft.com]
- Listas (SharePoint / Microsoft Lists): destino para almacenar resultados; se separa cabecera y detalle por modelado de datos. [learn.microsoft.com]
1) 🧠 AI Builder: creación de un modelo personalizado (Document Processing)
1.1 Inicio: AI hub → modelos → extracción personalizada
Se trabajó en el AI hub (Centro de IA) para crear un modelo de extracción personalizada porque permite entrenar con cualquier PDF que siga un patrón.[learn.microsoft.com]
1.2 Selección del tipo de documento (decisión importante)
Se revisaron las tres opciones del asistente: [learn.microsoft.com]
- Fixed template documents (Plantilla fija): ideal cuando los campos/tablas están en posiciones relativamente consistentes por layout (entrenamiento más rápido). [learn.microsoft.com]
- General documents: útil si no hay una estructura fija o hay variaciones fuertes (entrenamiento más largo). [learn.microsoft.com]
- Invoices: permite extender el modelo preconstruido de facturas (agregar campos o mejorar extracción). [learn.microsoft.com]
✅ En la práctica de la sesión se eligió Plantilla fija para trabajar con un formato consistente de documentos.[learn.microsoft.com]
2) 🧱 Definición del “esqueleto” de extracción: Cabecera + Detalle
2.1 Campos de cabecera (tipo de dato correcto)
Se definieron campos como (ejemplo trabajado):
- Texto: tipo de documento, número de documento, cliente, RUC/identificador, dirección, moneda. [learn.microsoft.com]
- Fecha: fecha de emisión (con formato acorde al documento). [learn.microsoft.com]
- Número: total IGV, importe total. [learn.microsoft.com]
🔎 Punto crítico: si el tipo de dato no coincide (ej. número como texto o fecha con formato incorrecto), la extracción puede fallar o traer errores. [learn.microsoft.com]
2.2 Tabla de detalle (líneas de ítems)
Para el detalle se usó un tipo de dato tabla, recomendada para información tabular. [learn.microsoft.com]
Columnas del detalle trabajadas:
- Texto: descripción, unidad de medida.
- Número: cantidad, valor de venta unitario, IGV, precio de venta unitario, valor de venta total.
✅ Buen enfoque: separar cabecera y detalle desde el modelo, porque el detalle es una colección de filas, no un solo registro. [learn.microsoft.com]
3) 🏷️ Etiquetado (Labeling): cómo “aprende” el modelo
3.1 Etiquetado de cabecera
Se realizó el match: seleccionar el texto en el PDF → asignarlo al campo correspondiente (ej. “Factura electrónica” → TipoDocumento). [learn.microsoft.com]
3.2 Etiquetado del detalle (tabla)
Para el detalle se enseñó a:
- Seleccionar el área de la tabla.
- Definir filas (cuántos ítems esperas).
- Definir columnas (mapeo de cada columna con su campo: descripción, cantidad, etc.).
📌 Recomendación operativa vista en la clase: si se crean líneas/columnas incorrectas, se puede quitar la etiqueta del detalle y rehacer el marcado más limpio.
4) 🧪 Entrenamiento, validación y publicación del modelo
4.1 Cantidad de documentos para entrenar
- Se reforzó que se deben cargar mínimo 5 documentos y, en práctica, usar más (ej. 8–10) mejora la precisión. [learn.microsoft.com], [learn.microsoft.com]
4.2 Entrenar y probar
- Entrenar el modelo y validar resultados (incluye revisión de calidad/precisión por campo). [learn.microsoft.com]
- Si el modelo muestra discrepancias, suele deberse a errores de etiquetado y conviene corregir etiquetas y re-entrenar. [learn.microsoft.com]
4.3 Publicar (requisito para usar en flujos)
- El modelo debe estar Publicado para poder utilizarse en Power Automate. [learn.microsoft.com], [learn.microsoft.com]
5) 🗂️ Diseño de almacenamiento: Listas para cabecera y detalle
5.1 ¿Por qué 2 listas?
- Una lista para cabecera y otra para detalle, porque el detalle contiene múltiples registros por documento. [learn.microsoft.com]
5.2 Estructura sugerida (alineada al modelo)
Lista Cabecera (ejemplo):
- TipoDocumento (texto), NumeroDocumento (texto), FechaEmision (fecha), Cliente (texto), RUC (texto), Dirección (texto), Moneda (texto), TotalIGV (número), ImporteTotal (número).
Lista Detalle (ejemplo):
- TipoDocumento (texto), NumeroDocumento (texto) + Descripción (texto), Medida (texto), Cantidad (número), ValorVentaUnitario (número), IGV (número), PrecioVentaUnitario (número), ValorVentaTotal (número).
✅ Clave técnica: incluir TipoDocumento + NumeroDocumento en Detalle para “relacionar” filas con su cabecera (clave de vínculo).
6) ⚡ Flujo en Power Automate: Email → Adjuntos → AI Builder → SharePoint
6.1 Tipo de flujo y desencadenador
Se creó un flujo de nube automatizado con el disparador When a new email arrives (V3), filtrando por:
- Subject filter (asunto específico)
- Has attachment / Only with attachments (solo con adjuntos) [learn.microsoft.com]
📨 Outlook.com vs Office 365 Outlook (punto clave)
- Office 365 Outlook es el conector recomendado para cuentas corporativas (trabajo/escuela). [learn.microsoft.com]
- Outlook.com es para cuentas personales, y puede generar problemas si se usa con correo corporativo. [learn.microsoft.com]
6.2 Obtención de adjuntos
Se usó la acción para recuperar adjuntos del correo; el flujo crea un Apply to each automáticamente porque un correo puede traer uno o varios archivos.[learn.microsoft.com]
6.3 AI Builder en el flujo: Process documents
Se aplicó la acción Process documents (antes llamada “Extract information from documents”) seleccionando:
- El modelo publicado
- Tipo de documento (PDF)
- Form / File content = contenido del adjunto [learn.microsoft.com]
✅ Buenas prácticas del output:
- Para registrar datos, elegir siempre “{campo} value” (y usar confidence score solo si deseas validación adicional). [learn.microsoft.com]
6.4 Escritura en listas: SharePoint “Create item”
- 1er Create item → lista Cabecera
- 2do Create item → lista Detalle, normalmente dentro de una iteración por filas/ítems del detalle (según cómo exponga la tabla el output). [learn.microsoft.com], [learn.microsoft.com]
📌 Regla práctica usada en clase:
- Campos “del detalle” se identifican como outputs que comienzan por detalle y terminan en value (según cómo el modelo nombra la tabla/campos). [learn.microsoft.com]
7) 💳 Créditos / capacidad de AI Builder (gobierno y costos)
Se conversó sobre consumo por “escaneo/procesamiento” y la necesidad de considerar costos en volumen.
✅ Refuerzo oficial (Microsoft):
- AI Builder usa créditos/capacidad que se asignan a entornos y se puede monitorear el consumo. [learn.microsoft.com]
- Parte de créditos “seeded” incluidos en licencias premium tienen fecha de retiro (según licenciamiento vigente) y se recomienda revisar el estado en el centro de administración. [learn.microsoft.com]
💡 Recomendación de clase: validar el costo real en tu escenario (volumen de documentos) y planificar consumo. [learn.microsoft.com]
❓ Preguntas y respuestas destacadas (con refuerzo oficial)
| Pregunta | Respuesta del docente (síntesis) | Refuerzo con documentación oficial |
|---|---|---|
| ¿Cuál opción elijo: plantilla fija, general o facturas? | Para el ejercicio se usó Plantilla fija; sirve cuando el documento mantiene posiciones similares. | Microsoft describe cuándo usar Fixed template / General / Invoices y su impacto en entrenamiento. [learn.microsoft.com] |
| ¿Cuántos documentos necesito para entrenar bien? | Mínimo 5; mejor con 8–10 para subir precisión. | Microsoft indica mínimo cinco ejemplos para iniciar y recomienda entrenar/pruebas. [learn.microsoft.com], [learn.microsoft.com] |
| ¿El OCR “calcula” subtotal o solo lee? | Solo extrae lo que existe en el documento; cálculos se hacen después en el flujo o en el destino. | AI Builder en flujos devuelve valores extraídos; no “inventa” campos no presentes. [learn.microsoft.com] |
| ¿Por qué Outlook.com no me funciona con mi correo corporativo? | Outlook.com es para cuentas personales; para corporativo se usa Office 365 Outlook. | Microsoft indica explícitamente cuándo usar Outlook.com vs Office 365 Outlook. [learn.microsoft.com] |
| ¿Por qué un campo sale con baja confianza (ej. RUC)? | Generalmente por etiquetado incorrecto en alguno de los documentos; entrenar con más ejemplos mejora. | Microsoft recomienda revisar etiquetado, calidad de ejemplos y reentrenar si hay errores. [learn.microsoft.com] |
| ¿Qué campo debo usar en el flujo: “text” o “value”? | Para guardar, usar value; “confidence score” es opcional para ver confianza. | La guía del action Process documents indica usar “{field} value” y permite usar “confidence score”. [learn.microsoft.com] |
✅ Conclusiones
- La sesión mostró un patrón muy usado en automatización: ingesta de documentos (correo) → IA (AI Builder) → persistencia estructurada (listas). [learn.microsoft.com]
- El éxito del modelo depende principalmente de:
- Campos bien definidos (tipo de dato correcto)
- Etiquetado consistente
- Entrenamiento con suficientes ejemplos [learn.microsoft.com], [learn.microsoft.com]
- Publicar el modelo es obligatorio para integrarlo en flujos y explotar outputs (value / tables) en acciones posteriores. [learn.microsoft.com], [learn.microsoft.com]
⭐ Recomendaciones finales
- 🧪 Entrena con variedad controlada: usa al menos 5 documentos, ideal 8–10, pero manteniendo el “mismo patrón” por colección. [learn.microsoft.com], [learn.microsoft.com]
- 🏷️ Etiqueta con precisión milimétrica: selecciona solo el valor (no títulos, no símbolos extra) para evitar baja confianza y errores de mapeo. [learn.microsoft.com]
- 📄 Usa páginas (Page range) en documentos grandes: reduce costo y mejora performance cuando el formulario está en rangos específicos. [learn.microsoft.com]
- 🗂️ Modela bien tus datos: dos listas (cabecera/detalle) y una clave de relación (Tipo + Número) evitan inconsistencias.
- 📨 Filtra en el trigger, no en condiciones posteriores: filtrar por asunto/adjuntos en el trigger evita ejecuciones innecesarias. [learn.microsoft.com], [learn.microsoft.com]
- 💳 Monitorea créditos/capacidad: antes de ir a producción, mide consumo y revisa la asignación por entorno. [learn.microsoft.com]
📚 Referencias oficiales
- Document processing (overview): https://learn.microsoft.com/en-us/ai-builder/form-processing-model-overview [learn.microsoft.com]
- Crear un modelo de document processing (custom): https://learn.microsoft.com/en-us/ai-builder/create-form-processing-model [learn.microsoft.com]
- Entrenar y publicar el modelo: https://learn.microsoft.com/en-us/ai-builder/form-processing-train [learn.microsoft.com]
- Usar el modelo en Power Automate (Process documents): https://learn.microsoft.com/en-us/ai-builder/form-processing-model-in-flow [learn.microsoft.com]
- Email triggers (filtrar por asunto/adjuntos): https://learn.microsoft.com/en-us/power-automate/email-triggers [learn.microsoft.com]
- Outlook en Power Automate (cuándo usar Office 365 vs Outlook.com): https://learn.microsoft.com/en-us/power-automate/email-overview [learn.microsoft.com]
- Créditos/capacidad AI Builder (licensing & consumption): https://learn.microsoft.com/en-us/ai-builder/credit-management [learn.microsoft.com]
- SharePoint connector (acciones/triggers): https://learn.microsoft.com/en-us/sharepoint/dev/business-apps/power-automate/sharepoint-connector-actions-triggers [learn.microsoft.com]